Render Tab
The render tab (called “Render Settings” in the title bar) contains the settings for selecting which listener object(s) to render from, as well as a variety of settings which adjust the quality of the rendered audio file.
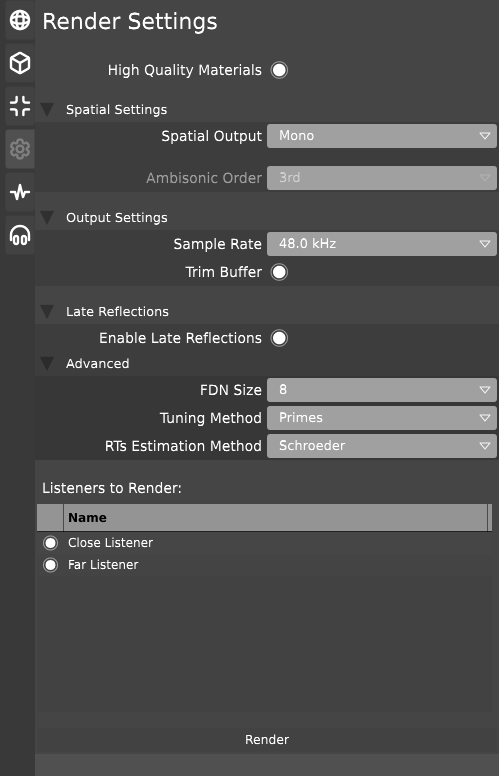
The “High Quality Materials” toggle swaps the materials rendering between a simplified “averaged” representation of all of the energies in the wide spectrum, and a version which takes the multiple bands of energies into a crossover system and more accurately represents the acoustic energy absorption across the spectrum.
Spatial Settings
The spatial output selector swaps between multiple methods of spatially rendering the output.
The default option is Mono, which produces a single channel audio file. Another option available is Stereo, which produces a double-channel audio output.
The Binaural & HQ Binaural options also produce double-channel audio outputs, but the audio is “binaurally decoded”, meaning that for headphone users, the listener will get the sensation that the audio is coming from a specific direction, as opposed to a general “left”, “right”, or “middle” location, as what would happen in stereo mode. This option is more recommended for headphone listeners, as the binaural effect does not translate to speaker-based setups.
Finally, there is an option for doing “Ambisonic” audio. This produces an audio file in the form of “B-Format”, which allows more advanced audio editors & tools to process the audio in more than a mono or stereo sound field.
A selector to adjust the order underneath becomes available when ambisonic mode is selected. Adjusting the “order” of the ambisonic output increases the complexity of the outputted signal in terms of channel count, where a 7th order ambisonic buffer (the maximum supported) provides a rendered audio file with 64 channels.
Ambisonic mode is ideal for multi-speaker setups.
Output Settings
The output settings section allows for the user to adjust more direct and low-level qualities of the outputted audio.
The sample rate selector changes the sampling rate of the output audio file. Increasing this value allows for an impulse response with much finer “time resolution”, as well as being able to recreate much higher frequencies, at the cost of a larger overall file. 44.1 kHz or 48 kHz is the typical setting that most end-users will find acceptable.
The “Trim Buffer” toggle changes whether or not the audio file will be trimmed down to remove excess silence at the end. The trimming occurs when audio goes below -80dB in volume. Otherwise, the rendered audio file will be the length of the longest early reflection + the maximum RT60 estimate (if early reflections are enabled).
Late Reflections
Late reflections exist to accentuate the limits of the acoustic simulation. This system adds additional diffused & scattered reflections based on the space’s estimated reverberant qualities, or based directly off the simulation results.
The FDN size adjusts the complexity of the reverberator. A higher size increases the rendering time, but also improves the reverb’s scattering density (and subsequently, it’s realism)
The tuning method adjusts how the short (under 10ms) delay values inside of the reverberator’s delay network will be set:
- The “Dynamic” method adjusts the tunings based on the delay lengths of the given render’s early reflections.
- The “Even” method spreads the delay times evenly between the internal minimum and maximum values
- The “Gaussian” method places the delay times in a gaussian distribution.
- The “Primes” method uses pre-calculated prime numbers which are guaranteed to not “intersect” with each other as the delays cycle through one another. This method is set as default as it tends to have the least amount of “ringing” and unwanted phase concurrency.
- The “Random” method picks delay lengths at random inside of the internal minimum and maximum values.
The “RTs Estimation Method” swaps between the two algorithms used for determining how long the reverb tail should be:
- The Schroeder method analyses the simulation at a given position, and predicts how long it will take before the values reach an inaudible level (RT60).
- The Sabine method roughly estimates the volume of the 3D space and determines the RT60 values based on the volume and the absorptive qualities of the space’s averaged material values.
The Schroeder method is considered to be more realistic, and can vary differently based on the position of the listener. The Sabine method’s RT60 estimations tend to be much longer than the Schroeder method.